Webスクレイピング!ネットの画像を一括ダウンロード: Python入門
記事のリニューアルに伴い、ページをこちらに移転いたしました。ご了承ください。
Pythonプログラム入門の1回目です。
Webスクレイピングにより、指定したURLから画像ファイルのみを抽出して自分のパソコンにダウンロードします。
- Webスクレイピングって??
- 必要なプログラムをインストールする
- プログラムの流れ
- コード全体
- BeautifulSoup のエラー "Couldn't find a tree builder"
- エラー2つ目 AttributeError: 'NoneType' object has no attribute 'endswith'
Webスクレイピングって??
scrape = 削り取るという意味ですが、、わたしはRubyプログラムをスクールで学んでいたとき、メンターの方から初めて聞いた言葉でした。
そのときは、スクールの課題でアプリをつくってたとき、URLからそのページのタイトルなどを取得できないものか?と相談した際に、スクレイピングというものがあるよと、教わりました。
Webスクレイピングとは、外部サーバへアクセスし、そのコンテンツから欲しい情報を引き出すプログラムのことです。
まさにわたしがやりたかったことだったので、それから しばらくWebスクレイピングにのめりこみました。
スクレイピングはハマリます!おもしろいですよ~
必要なプログラムをインストールする
Pythonのインストール
まずはPythonをインストールしましょう。
こちらの公式サイトから、Pythonのインストーラーをダウンロードできます。とくに理由がなければ最新版をおすすめします。
ご自身の環境(Windows 64ビットと32ビット、Mac OS)によってインストールの手順が変わります。下記の記事がとてもわかりやすく解説されておりましたので、よろしければご参考ください。
pipのインストール
Pythonには「モジュール」という便利なライブラリがあります。
Pythonに標準で付属している「組み込みモジュール」もあれば、あらたにインストールして利用できるものもあります。
モジュールもPythonのプログラムです。モジュールを利用することで、さまざまな機能が使えるようになります。
外部からモジュールをインストールするには、「pip」と呼ばれるプログラムを使います。そのため、まずpipプログラムをインストールしておく必要があります。
pipプログラムが外部ライブラリを管理するための機能となります。
・Windows - コマンドプロンプトで実行(エンターキー)
python -m pip install -U pip
・Mac - ターミナルで実行
python3 -m pip install -U pip
python XXXX…の「python」は、Pythonプログラムの実行コードです。Pythonをインストールしたことで、利用できるようになっています。
モジュール(ライブラリ)のインストール
pipプログラムのインストールが完了しましたら、引き続きコマンドプロンプト(Macだとターミナル)からモジュール「requests」と「bs4」をインストールしてください。
Pythonは、プログラムの内容によって、必要なモジュールをインストールして使います。
今回のプログラムでは、「requests」「bs4」の2つを追加します。
pipコマンドで「requests」「bs4」をインストール
pip install requests
pip install beautifulsoup4
プログラムの流れ
それでは、コードを見ていきましょう。
1.モジュールのインポート
import requests # urlを読み込むのに必要 from bs4 import BeautifulSoup # htmlを読み込むのに必要 import os
上記がプログラムの冒頭です。importの命令文で、今回利用するモジュールを呼び出しています。
「# urlを読み込む…」などの部分はコメントです。Pythonプログラム内では「#」を文頭につけることで、コメントアウトされます。
- requests - URLを読み込む。
- BeautifulSoup - URLを指定して取得した、サイトページのHTMLを解析する。
- os - プログラムファイルがある場所に、画像を保存するフォルダを作成する。
※「os」は、標準ライブラリ(組み込みモジュール)として組み込まれています。
2. ページURLとリストimagesを定義する
try:
os.mkdir("img") # プログラムファイルのある場所にフォルダ「img」を作成
except:
pass # すでに「img」フォルダがある場合、作成をスキップ
URL = "任意のアドレス" # URL入力
images = [] # 画像リストの配列
ダウンロードした画像を保存するため、フォルダ名imgをPythonプログラムの実行ファイルのある場所に作成します。
「try:~except:」というのは例外処理の構文で、try:以下の処理を実行したときにエラーとなる場合、プログラムをストップせずexcept:以下の処理に移行して実行するものです。
except:以下に「pass」句を使用しているため、エラーが発生しても何も処理を行いません。
この場合、「os.mkdir("img")」でimgフォルダの作成を実行したとき、imgフォルダがすでにあるとエラーが発生しますが、try:~except:構文のおかげでプログラムが停止することなく、そのまま処理が継続されます。
そして画像をダウンロードするページのURLと、リストであるimagesを変数として定義します。
3. モジュールbs4により、HTMLを解析する
soup = BeautifulSoup(requests.get(URL).content,'lxml') # bsでURL内を解析
「requests」で取得したHTML情報を「BeautifulSoup」で解析し、解析したデータを変数soupに格納します。
4. 画像ファイル .jpgと .pngを取得する
for link in soup.find_all("img"): # imgタグを取得しlinkに格納
if link.get("src").endswith(".jpg"): # imgタグ内の.jpgであるsrcタグを取得
images.append(link.get("src")) # imagesリストに格納
elif link.get("src").endswith(".png"): # imgタグ内の.pngであるsrcタグを取得
images.append(link.get("src")) # imagesリストに格納
for文を利用し、変数soup内にあるデータから .jpgファイルと .pngファイルを抽出し、リストimagesに格納します。
5. imgフォルダ作成と画像ファイルの保存
for target in images: # imagesからtargetに入れる
re = requests.get(target)
with open('img/' + target.split('/')[-1], 'wb') as f: # imgフォルダに格納
f.write(re.content) # .contentにて画像データとして書き込む
for文を利用し、リストimages内に格納している画像データを、with open関数を利用して1ファイルごとに保存していきます。
コード全体
コードの全体です。
プログラムの実行
上のソースコードを、メモ帳などのテキストエディタに貼り付け、「XXXXXX.py」とPythonプログラムファイルの拡張子「.py」をつけて適当なフォルダに保存してください。ファイル名は、任意のものでかまいません。
ファイルを保存したらコマンドプロンプト(Macだとターミナル)を起動し、保存したフォルダの場所に移動してから以下を実行してください。
python ファイル名.py
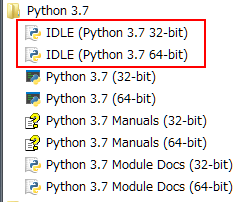
「IDLE」アプリケーション
コマンドプロンプトだとイマイチ使いづらい、というかたは、Pythonをインストールした際に一緒にインストールされている「IDLE」というプログラムファイルから実行する方法がありますので、そちらを起動してください。
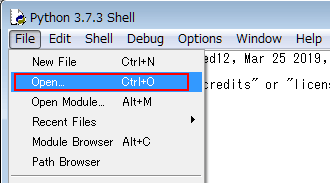
実行結果
画像を一括ダウンロードするページのURLに、姉妹ブログ「ながカフェ」のアドレスを指定して実行した結果です。
NAGA CAFE
URLを入力する場所は、コードの
URL = "任意のアドレス" # URL入力
の"任意のアドレス"の部分です。ながカフェの場合
URL = "https://naga-cafe.blogspot.com" # URL入力
となります。
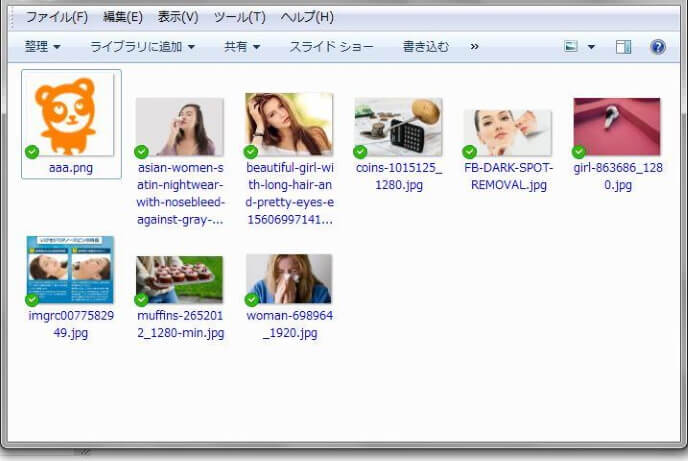
無事、画像ファイルを取得できました!
今回はここで終了です。ここまでご覧いただき、ありがとうございました。
おつかれさまでした。
BeautifulSoup のエラー "Couldn't find a tree builder"
/* 2023年8月21日追記 */
問題
久しぶりに上に紹介したプログラムを実行したところ、
「Do you need to install a parser library?(パーサーライブラリをインストールする必要がありますか?)」というエラーが出ました。
Python 3 で BeautifulSoup 4 を呼び出すとき、
soup = BeautifulSoup(html, "lxml")
以下のエラーが発生することがあるようです。
Couldn't find a tree builder with the features you requested: lxml. Do you need to install a parser library?
原因
パーサーライブラリをインストールしていなかった。
BeautifulSoup はパーサーとして html.parser, lxml, html5lib などをサポートしていますが、そのうち標準で含まれているのは html.parser だけで、lxml などは BeautifulSoup の依存パッケージに含まれないので、別途インストールが必要とのことです。
対処法
lxml パッケージをインストールする。
$ pip install lxml
これで無事、画像をダウンロードできました!
エラー2つ目 AttributeError: 'NoneType' object has no attribute 'endswith'
「属性エラー: 'NoneType' オブジェクトには 'endswith' 属性がありません。」
問題
17行目と19行目で
if link.get("src").endswith(".jpg"): # imgタグ内の.jpgであるsrcタグを取得
elif link.get("src").endswith(".png"): # imgタグ内の.pngであるsrcタグを取得
同様のエラーが2か所で出ました。
原因&対処法
17行目
if link.get("src").endswith(".jpg"): # imgタグ内の.jpgであるsrcタグを取得
を、
if link.get("src") and link.get("src").endswith(".jpg"):
に変更。
19行目
elif link.get("src").endswith(".png"): # imgタグ内の.pngであるsrcタグを取得
を、
elif link.get("src") and link.get("src").endswith(".png"):
に変更。
取得先(11行目の ”URL = "任意のアドレス" # URL入力” の部分)によっては上記エラーが発生するようです。
出た際は、このようにコードを変更して試してみて下さい。
/* 2023年8月21日追記ここまで */
参考図書

よろしければ、下記の投稿もごらんください↓



コメント
コメントを投稿